

Zuletzt aktualisiert am

Das Wichtigste in Kürze
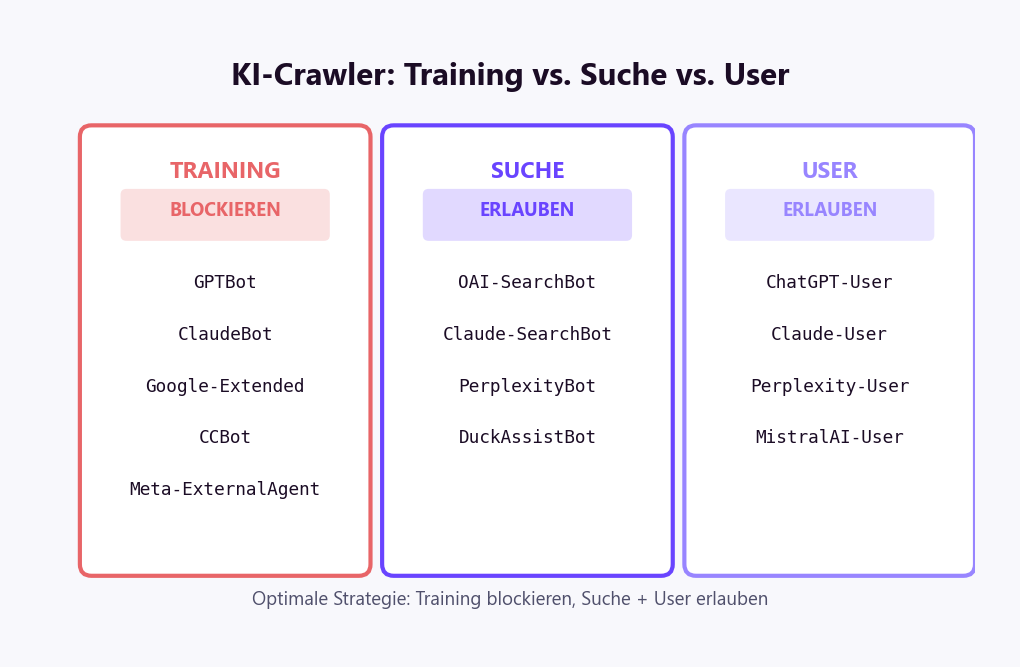
Kurz gesagt: Eine robots.txt für KI-Crawler steuerst du am besten in drei Stufen. Such-Crawler, die qualifizierten Traffic liefern (OAI-SearchBot, ChatGPT-User, PerplexityBot, Claude-SearchBot), erlaubst du mit Allow: /. Reine Training-Crawler (GPTBot, ClaudeBot, Google-Extended, CCBot, Meta-ExternalAgent) blockierst du mit Disallow: /. Aggressive Bots, die Server belasten (Bytespider, ImagesiftBot), sperrst du grundsätzlich aus. So behältst du KI-Sichtbarkeit und kontrollierst zugleich, womit Modelle trainiert werden. Die fertige Konfiguration zum Kopieren steht weiter unten.
158 dokumentierte Bots.
So viele KI-Crawler listet das ai.robots.txt GitHub-Repository im März 2026. Von GPTBot über ClaudeBot bis zu Bytespider, Meta-ExternalAgent und Dutzenden weiteren. Jeder will deine Inhalte — aber nicht jeder gibt etwas zurück. Manche trainieren Modelle mit deinem Content. Andere liefern dir qualifizierten Traffic. Und einige tun beides.
Das Problem: Die meisten robots.txt-Konfigurationen sind veraltet. Sie kennen GPTBot, vielleicht ClaudeBot — und ignorieren die restlichen 155 Crawler. Das Ergebnis ist entweder ein offenes Tor für KI-Training oder eine Mauer, die auch die Suche blockiert. Beides kostet dich Geld.
5,6 Millionen Websites blockieren GPTBot — ein Anstieg von 70 % in einem Jahr (Search Engine Journal). 79 % der Top-Nachrichtenseiten sperren mindestens einen KI-Bot aus (BuzzStream). Aber die entscheidende Frage ist nicht „blockieren oder nicht“. Die Frage ist: Welche Bots blockierst du — und welche lässt du rein?
Die detaillierten Nutzerzahlen aller KI-Suchmaschinen findest du in unserem GEO-Statistiken-Artikel. Wie KI-Suchmaschinen technisch funktionieren, erklärt unser vollständiger GEO-Guide. Dieser Artikel zeigt dir, wie du deine robots.txt so konfigurierst, dass du KI-Training kontrollierst, ohne KI-Sichtbarkeit zu verlieren.
Drei Kategorien.
KI-Crawler lassen sich in drei Gruppen einteilen — und diese Unterscheidung ist die Basis jeder sinnvollen robots.txt-Konfiguration:
| Kategorie | Zweck | Blockieren = |
|---|---|---|
| Training-Crawler | Sammeln Inhalte für das Training von KI-Modellen | Kein Training mit deinem Content |
| Such-Crawler | Indexieren Inhalte für KI-Suchergebnisse | Unsichtbar in ChatGPT Search, Claude, Perplexity |
| User-Crawler | Rufen Seiten ab, wenn ein Nutzer danach fragt | Seite kann nicht geladen werden bei Nutzeranfragen |
| Bot | User-Agent-Token | Zweck | robots.txt? |
|---|---|---|---|
| GPTBot | GPTBot |
Training für GPT-Modelle | Ja |
| OAI-SearchBot | OAI-SearchBot |
ChatGPT-Suchfunktionen (NICHT Training) | Ja |
| ChatGPT-User | ChatGPT-User |
Nutzer-ausgelöste Abfragen | Bedingt* |
*ChatGPT-User wird durch echte Nutzeranfragen ausgelöst — robots.txt-Regeln gelten laut OpenAI „möglicherweise nicht“. Wichtig: OAI-SearchBot und GPTBot teilen Informationen. Wenn du beide erlaubst, crawlt OpenAI nur einmal für beide Zwecke — weniger Serverlast.
Die ChatGPT-spezifische Optimierung haben wir in unserem ChatGPT SEO Guide detailliert behandelt.
| Bot | User-Agent-Token | Zweck | robots.txt? |
|---|---|---|---|
| ClaudeBot | ClaudeBot |
Training für Claude-Modelle | Ja (+ Crawl-delay) |
| Claude-SearchBot | Claude-SearchBot |
Indexierung für Claude-Suche | Ja |
| Claude-User | Claude-User |
Nutzer-ausgelöste Abfragen | Ja |
Anthropic hat im Februar 2026 als erster Anbieter ein klares 3-Bot-Framework eingeführt. Jeder Bot ist einzeln blockierbar. ClaudeBot unterstützt als einer der wenigen KI-Crawler auch Crawl-delay.
| Bot | User-Agent-Token | Zweck | Blockieren = |
|---|---|---|---|
| Google-Extended | Google-Extended |
Gemini/Vertex AI Training | Kein Gemini-Training. Google Search + AI Overviews BLEIBEN. |
| Googlebot | Googlebot |
Google Search + ALLES | ALLES weg — Search, AI Overviews, Maps, alles. |
| GoogleOther | GoogleOther |
Interne Forschung | Kein Einfluss auf Search |
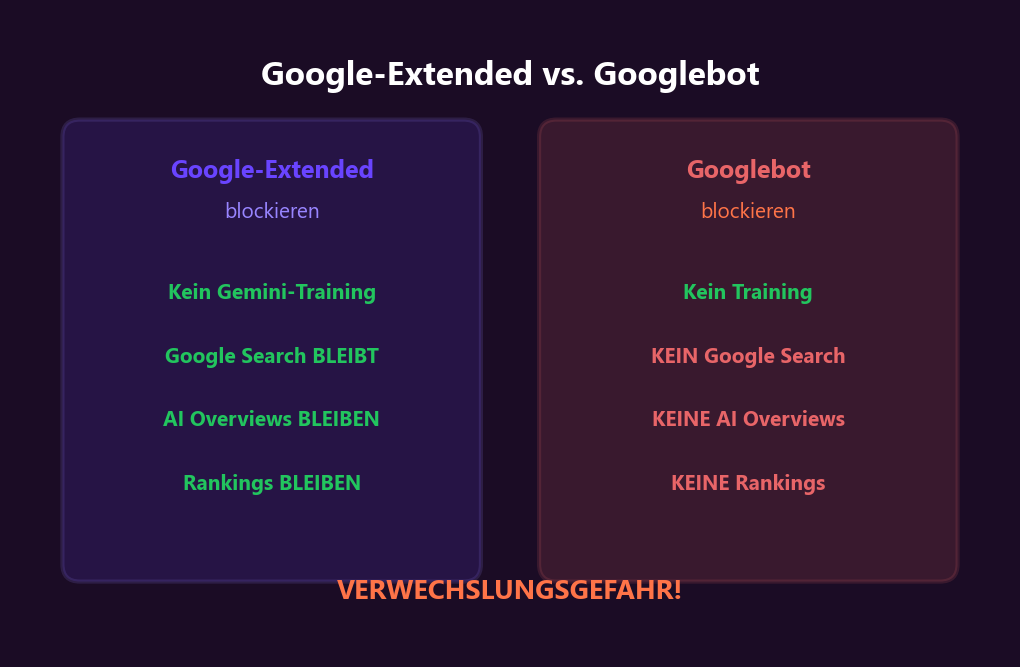
Der häufigste Fehler: Googlebot statt Google-Extended blockieren. Das zerstört deine gesamte Google-Sichtbarkeit — Rankings, AI Overviews, Featured Snippets, alles. Google-Extended blockiert NUR das Training für Gemini. Google Search bleibt unberührt. Das haben wir in unserem AI Overviews Guide ausführlich erklärt.
| Bot | User-Agent-Token | Zweck | robots.txt? |
|---|---|---|---|
| PerplexityBot | PerplexityBot |
Automatische Indexierung | Offiziell ja — aber kontrovers |
| Perplexity-User | Perplexity-User |
Nutzer-ausgelöste Abfragen | Ignoriert robots.txt |
Perplexitys Crawler-Verhalten ist umstritten. Cloudflare hat dokumentiert, dass Perplexity undeklierte Crawler nutzt, die sich als Chrome-Browser tarnen (Cloudflare Blog, August 2025). Die BBC blockiert PerplexityBot — und wird trotzdem am häufigsten von Perplexity zitiert (Press Gazette). Details dazu in unserem Perplexity Optimierung Guide.
| Bot | Betreiber | Zweck | Warnung |
|---|---|---|---|
| Meta-ExternalAgent | Meta | LLaMA-Training, Meta AI | ~52 % des gesamten KI-Crawler-Traffics. Nur 2 % der Websites blockieren ihn. |
| Bytespider | ByteDance (TikTok) | LLM-Training | 25× aggressiver als GPTBot. Bis zu 1,4 Mio. Requests/Tag. ~90 % des KI-Crawler-Traffics bei manchen Hosts. |
| Applebot-Extended | Apple | Apple Intelligence Training | Blockieren hat keinen Einfluss auf Siri/Spotlight. |
| CCBot | Common Crawl | Open-Source-Webarchiv | Von vielen KI-Firmen für Training genutzt. |
| Amazonbot | Amazon | Alexa, Rufus KI | — |
| Bingbot | Microsoft | Bing Search + Copilot | NICHT separat für Suche/KI blockierbar. Blockieren = keine Bing-Sichtbarkeit. |
| GrokBot | xAI (Elon Musk) | Grok-Training | Nutzt iPhone User-Agent zur Umgehung. Nicht zuverlässig blockierbar. |
Blockierst du alles oder nichts?
Die meisten Websites machen einen von zwei Fehlern: Entweder sie blockieren alle KI-Crawler — und verlieren KI-Sichtbarkeit. Oder sie blockieren keinen — und ihr Content trainiert Modelle ohne Gegenleistung. Die Lösung liegt dazwischen. Ergänzend dazu erklären wir, wie du llms.txt richtig einsetzen kannst — und warum die Datei die robots.txt nicht ersetzt.
Seit 2025/2026 trennen OpenAI, Anthropic und Google ihre Crawler sauber in Training und Suche. Das bedeutet: Du kannst das Training blockieren und die Suche erlauben. Das ist die Konfiguration, die für die meisten Unternehmen am meisten Sinn ergibt.
| Was du blockierst | Auswirkung |
|---|---|
| GPTBot | Kein Training. ChatGPT-Suche bleibt aktiv. |
| OAI-SearchBot | Unsichtbar in ChatGPT Search. |
| ClaudeBot | Kein Training. Claude-Suche bleibt aktiv. |
| Claude-SearchBot | Reduzierte Sichtbarkeit in Claude-Suchergebnissen. |
| Google-Extended | Kein Gemini-Training. Google Search + AI Overviews bleiben. |
| Googlebot | ALLES weg. Nie blockieren. |
| PerplexityBot | Sollte Indexierung verhindern — aber BBC wird trotzdem zitiert. |
Pixelmojo hat es getestet: 12 Training-Crawler blockiert, Such-Bots erlaubt. Ergebnis: „Citations kept growing“ und „server load dropped.“ Die Bestätigung: Training-Bots blockieren schadet der Suchsichtbarkeit NICHT (Pixelmojo Case Study).
KI-Referral-Traffic wächst mit +527 % pro Jahr. ChatGPT macht 77,97 % dieses Traffics aus, Perplexity 15,10 %, Gemini 6,40 % (Conductor). Und dieser Traffic konvertiert: 15,9 % bei ChatGPT, 10,5 % bei Perplexity — deutlich höher als organischer Google-Traffic (SuperPrompt/Coalition Technologies). Wer Such-Bots blockiert, verliert diesen Traffic.
Die Princeton-GEO-Studie hat gezeigt, welche Content-Methoden die Zitationswahrscheinlichkeit steigern. Den vollständigen Überblick findest du in unserem Artikel zur Princeton-Studie.
Copy. Paste. Fertig.
Hier ist die robots.txt-Konfiguration, die wir empfehlen — basierend auf den aktuellen Bot-Dokumentationen, der Drei-Tier-Strategie und den Daten aus 200+ Projekten:
# ===== KI-SUCH-CRAWLER (ERLAUBEN für Sichtbarkeit) =====
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: DuckAssistBot
Allow: /
User-agent: MistralAI-User
Allow: /# ===== KI-TRAINING-CRAWLER (BLOCKIEREN) =====
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: cohere-training-data-crawler
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: FacebookBot
Disallow: /
User-agent: Diffbot
Disallow: /
User-agent: AI2Bot
Disallow: /
User-agent: AI2Bot-Dolma
Disallow: /# ===== AGGRESSIVE BOTS (IMMER BLOCKIEREN) =====
User-agent: Bytespider
Disallow: /
User-agent: TikTokSpider
Disallow: /
User-agent: ImagesiftBot
Disallow: /
User-agent: img2dataset
Disallow: /
User-agent: Omgilibot
Disallow: /
User-agent: omgili
Disallow: /
User-agent: ICC-Crawler
Disallow: /
User-agent: Timpibot
Disallow: /
User-agent: VelenPublicWebCrawler
Disallow: /
User-agent: PanguBot
Disallow: /
User-agent: Kangaroo Bot
Disallow: /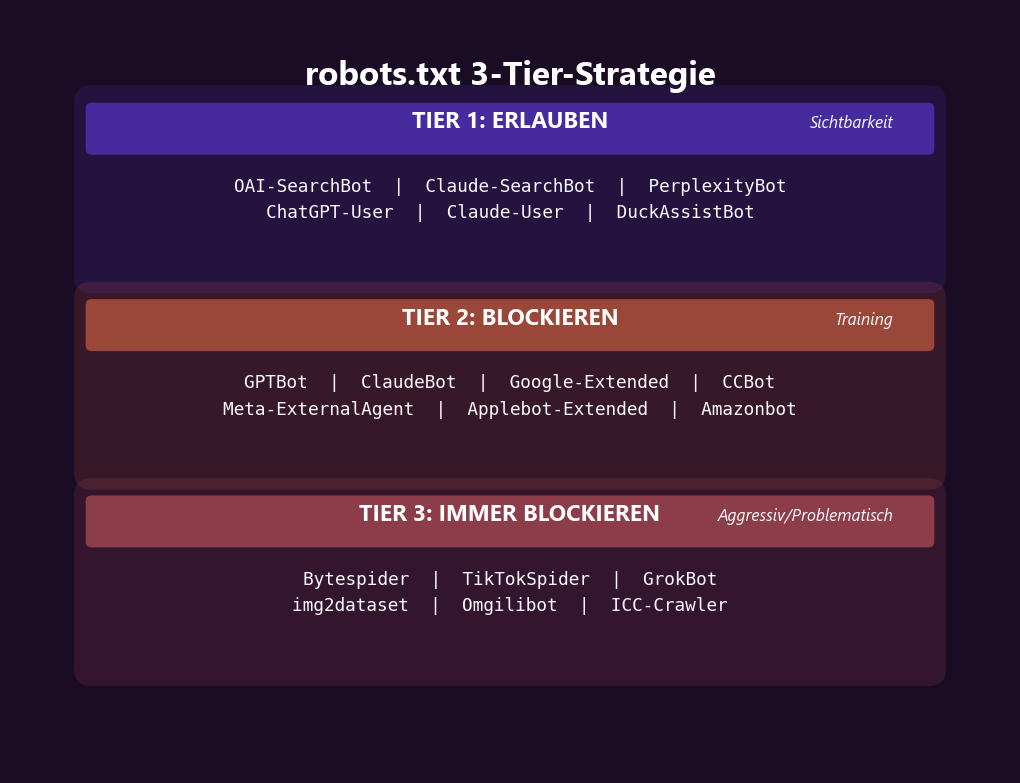
Wichtig: Die Konfiguration geht davon aus, dass du Googlebot und Bingbot NICHT blockierst. Falls deine robots.txt ein generisches User-agent: * / Disallow: / enthält, überschreibt das ALLES — auch die spezifischen Allow-Regeln. Prüfe deine bestehende robots.txt bevor du diese Einträge hinzufügst.
Die robots.txt-Konfiguration ist ein Baustein einer gesamten KI-Sichtbarkeits-Strategie — Schema Markup, Content-Struktur und Plattform-spezifische Maßnahmen gehören dazu. Den Zusammenhang beschreiben wir auf unserer Seite zur GEO-Agentur.
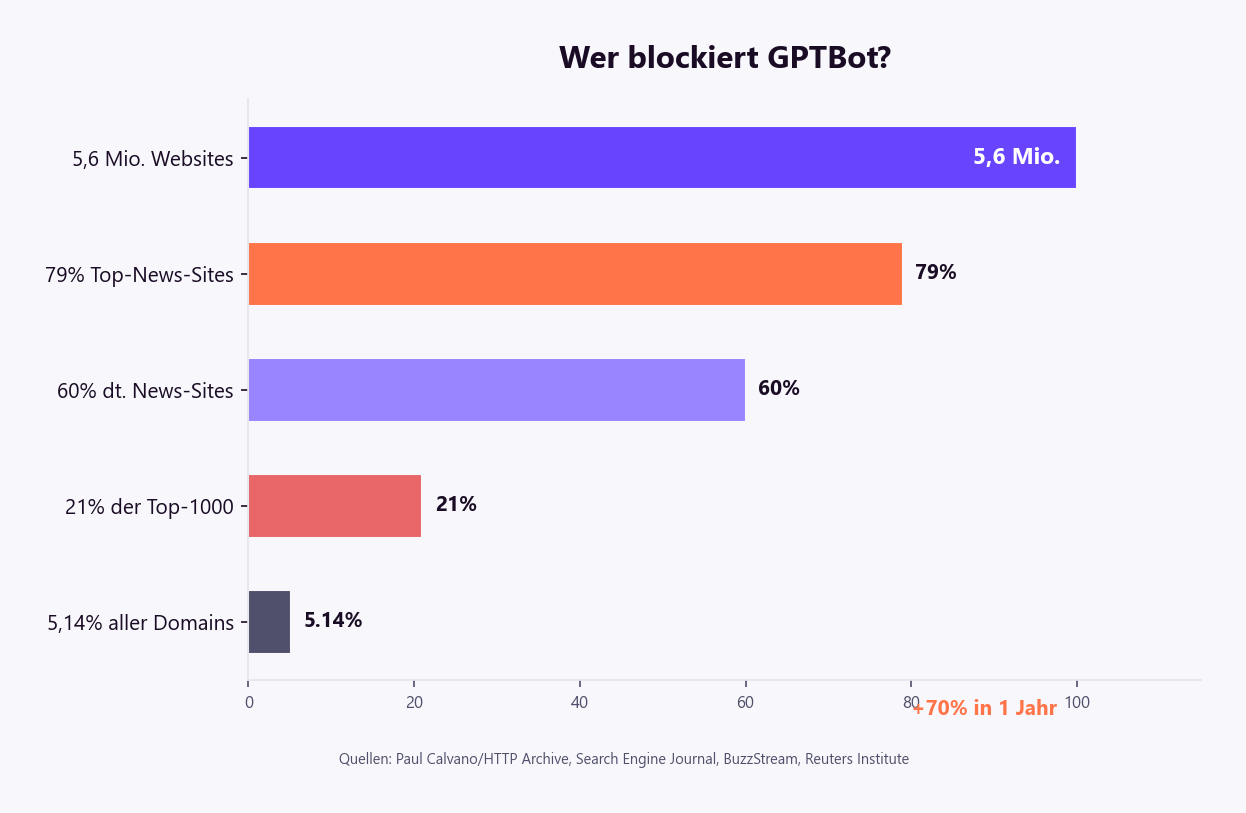
70 % Anstieg in einem Jahr.
Die Blocking-Statistiken zeigen ein klares Bild — und eine überraschende Entwicklung (Paul Calvano/HTTP Archive, Search Engine Journal, BuzzStream):
| Metrik | Wert | Quelle |
|---|---|---|
| Websites die GPTBot blockieren | 5,6 Mio. | Search Engine Journal, 2025 |
| Anstieg in 1 Jahr | +70 % (von 3,3 Mio.) | Search Engine Journal |
| GPTBot Blocking-Rate (alle Domains) | 5,14 % | Paul Calvano/HTTP Archive |
| Top-1000-Websites mit GPTBot-Block | 21 % (312 Domains) | Paul Calvano, Juli 2025 |
| Top-News-Sites mit mind. 1 KI-Block | 79 % | BuzzStream |
| KI-Crawler-Blocking gesamt (Anstieg) | +336 % in einem Jahr | engagecoders.com |
| Bot | Blocking-Rate (News-Sites) | Typ |
|---|---|---|
| ClaudeBot (Training) | 69 % | Training |
| GPTBot (Training) | 62 % | Training |
| OAI-SearchBot (Suche) | 49 % | Suche |
| ChatGPT-User | 40 % | User |
Der Trend ist klar: Training-Bots werden häufiger blockiert als Such-Bots. Verlage unterscheiden bereits — und verlieren dadurch weniger KI-Sichtbarkeit als Websites, die alles blockieren.
Laut Reuters Institute blockieren 60 % der deutschen Nachrichtenseiten sowohl OpenAI als auch Google AI Crawler. Zum Vergleich: In den USA sind es 79 % für OpenAI, in Mexiko nur 20 %. Deutsche Verlage gehören zu den restriktivsten weltweit — was Chancen für Unternehmen eröffnet, die ihre KI-Sichtbarkeit bewusst aufbauen.
Das Fazit aus den GEO vs. SEO Unterschieden: Wer heute die robots.txt strategisch konfiguriert, hat einen Wettbewerbsvorteil gegenüber der Mehrheit, die entweder alles blockiert oder die Konfiguration ignoriert.
Drei Schutzschichten.
robots.txt ist nicht die einzige Möglichkeit, KI-Crawler zu steuern. Für umfassende Kontrolle gibt es drei Methoden — jede mit eigenen Stärken:
| Methode | Ebene | Wann gelesen | Vorteil |
|---|---|---|---|
| robots.txt | Domain/Pfade | VOR dem Seitenaufruf | Effizienteste Methode — verhindert Crawling komplett |
| Meta Robots Tag | Einzelne Seite | NACH dem Seitenaufruf | Granulare Kontrolle pro Seite |
| X-Robots-Tag | HTTP Header | Bei jedem Request | Funktioniert auch für PDFs, Bilder, Nicht-HTML |
DeviantArt hat im November 2022 zwei Meta Tags eingeführt, die von mehreren KI-Crawlern respektiert werden:
<meta name="robots" content="noai, noimageai">noai signalisiert: Kein Inhalt dieser Seite soll für KI-Training genutzt werden. noimageai gilt speziell für Bilder. Wichtig: Diese Tags sind kein offizieller Webstandard. Die Beachtung ist freiwillig. Laut AmIcited respektieren GPTBot, ClaudeBot, PerplexityBot, Amazonbot, Google-Extended und weitere diese Tags — aber eine Garantie gibt es nicht.
Keine einzelne Methode ist 100 % sicher. robots.txt ist freiwillig — aggressive Bots wie Bytespider oder GrokBot umgehen sie nachweislich. Für echte Durchsetzung brauchst du Server-Level-Blocking über Cloudflare, .htaccess oder Nginx-Regeln.
1,4 Millionen Requests. Pro Tag. Von einem einzigen Bot.
Das ist Bytespider — TikToks Mutterkonzern ByteDance. Bei HAProxy machte Bytespider „nahezu 90 % des gesamten KI-Crawler-Traffics“ aus. Und er ist 25× aggressiver als GPTBot (NusaPixel). Das ist kein Edge Case — das ist Realität für viele mittelgroße Websites.
| Metrik | Wert | Quelle |
|---|---|---|
| GPTBot monatliche Requests | 569 Mio. | Vercel |
| ClaudeBot monatliche Requests | 370 Mio. | Vercel |
| KI-Crawler Anteil am HTML-Traffic | ~8,7 % | Cloudflare 2025 |
| Read the Docs: Traffic nach Blocking | -75 % (800→200 GB/Tag) | Read the Docs Blog |
Read the Docs hat KI-Crawler blockiert und die Bandbreite von ~800 GB/Tag auf ~200 GB/Tag reduziert — eine Einsparung von ~1.500 $/Monat. Publisher berichten von 20-40 % der gesamten Bandbreite durch KI-Crawler.
Was du dagegen tun kannst:
Zero Besuche.
Semrush hat llms.txt auf Search Engine Land implementiert und die Server-Logs von August bis Oktober 2025 analysiert. Das Ergebnis: Kein einziger KI-Crawler (GPTBot, ClaudeBot, PerplexityBot, Google-Extended) hat die Datei besucht. Null. Google John Mueller bestätigte: „FWIW no AI system currently uses llms.txt.“
llms.txt ist ein Vorschlag von Jeremy Howard (Co-Founder Answer.AI, September 2024). Eine Markdown-Datei im Root-Verzeichnis, die KI-Systemen eine kuratierte Übersicht der Website bietet — wie eine Landkarte für LLMs. ~844.000 Websites haben sie implementiert (BuiltWith, Oktober 2025).
# Firmenname
> Kurze Beschreibung der Website
## Hauptinhalte
- [Seite 1](https://url): Beschreibung
- [Seite 2](https://url): Beschreibung
## Optional
- [Weitere Seite](https://url): BeschreibungPro: Niedrige Implementierungskosten, zukunftssicher falls der Standard adoptiert wird. Contra: Kein einziger großer KI-Anbieter (OpenAI, Google, Anthropic) nutzt llms.txt offiziell in Produkten. Keine messbaren Auswirkungen auf KI-Sichtbarkeit nachgewiesen.
Unsere Empfehlung: Nice-to-have für Developer und SaaS. Aber investiere deine Zeit lieber in robots.txt-Konfiguration und Content-Optimierung — das hat nachweislich Impact. Wie genau du zitierfähigen Content erstellst, zeigt die Princeton-GEO-Studie.
Seit August 2025 quasi-verbindlich.
robots.txt war 30 Jahre lang ein freiwilliges Protokoll. Der EU AI Act hat das geändert. Artikel 53 verpflichtet Anbieter von General Purpose AI (GPAI) Modellen, Copyright-Policies zu implementieren und Rechtsvorbehalte zu respektieren — inklusive robots.txt-Dateien gemäß RFC 9309 (GPAI Code of Practice, finalisiert Juli 2025).
Was das konkret bedeutet: Wenn du in deiner robots.txt GPTBot: Disallow: / einträgst, sind OpenAI, Anthropic und andere GPAI-Anbieter in der EU rechtlich verpflichtet, das zu respektieren. Zum ersten Mal hat robots.txt damit tatsächliche rechtliche Bedeutung.
| Fall | Status | Relevanz für robots.txt |
|---|---|---|
| NYT vs. OpenAI | Discovery-Phase (seit 2023) | Gericht: robots.txt ist „eher ein Schild als eine Barriere“ — kein technischer Schutz |
| LG Hamburg (LAION) | Klage abgewiesen (Nov. 2025) | Wissenschaftliches TDM ohne robots.txt-Beachtung kann zulässig sein |
| Reddit vs. Perplexity | Laufend (seit Okt. 2025) | Umgehung von robots.txt als Klagegrund |
Fazit: robots.txt allein schützt nicht rechtlich. Aber in Kombination mit dem EU AI Act, DSGVO und expliziten Copyright-Hinweisen auf deiner Website hast du eine deutlich stärkere Position als ohne. Die Kombination aus technischer Blockierung (robots.txt + Server-Level) und rechtlicher Dokumentation (Copyright-Notice, TDM-Opt-out) ist die sicherste Strategie.
Ob SEO insgesamt noch relevant ist oder KI-Suche alles verändert, haben wir datenbasiert in unserem Artikel Ist SEO tot? analysiert.
Nicht raten — systematisch vorgehen.
deine-domain.de/robots.txt im Browser. Gibt es bereits KI-Crawler-Einträge? Gibt es ein generisches Disallow: / das alles blockiert? Fehler in der Syntax?
Die robots.txt-Konfiguration ist ein wichtiger Teil deiner GEO-Strategie — aber nur ein Teil. Schema Markup, Content-Optimierung und Plattform-spezifische Maßnahmen gehören ebenfalls dazu. Den vollständigen Überblick findest du in unserem kompletten GEO-Guide. Und wenn du das nicht allein umsetzen willst: Mehr zu unserer GEO-Agentur.
Nicht zwingend — ohne Einträge crawlen KI-Bots deine Website automatisch. Aber ohne Konfiguration verlierst du die Kontrolle darüber, welche Crawler deine Inhalte für Training nutzen. Seit dem EU AI Act (August 2025) sind GPAI-Anbieter verpflichtet, robots.txt gemäß RFC 9309 zu respektieren. Eine bewusste Konfiguration ist also empfehlenswert.
GPTBot crawlt für das Training von GPT-Modellen. OAI-SearchBot indexiert für ChatGPT-Suchfunktionen — ohne die Daten für Training zu nutzen. Du kannst GPTBot blockieren (kein Training) und OAI-SearchBot erlauben (Sichtbarkeit in ChatGPT Search behalten). Beide teilen Informationen: Wenn du beide erlaubst, crawlt OpenAI nur einmal für beide Zwecke.
Google-Extended blockieren verhindert, dass deine Inhalte für Gemini/Vertex AI Training genutzt werden. Es hat KEINEN Einfluss auf Google Search, AI Overviews oder andere Google-Produkte. Googlebot ist der Crawler für Search — Google-Extended ist nur ein Token für Training-Kontrolle. NIEMALS Googlebot blockieren, wenn du Google-Sichtbarkeit behalten willst.
Die meisten großen Anbieter (OpenAI, Anthropic, Google, Apple, Amazon) respektieren robots.txt offiziell. Problematisch sind: Bytespider (TikTok/ByteDance) — Berichte über Missachtung und User-Agent-Fälschung. GrokBot (xAI) — nutzt iPhone User-Agent zur Umgehung. Perplexity — Cloudflare hat undeclared Crawler dokumentiert. Für diese Bots brauchst du Server-Level-Blocking.
Mindestens quartalsweise. Neue KI-Crawler erscheinen ständig — allein 2025/2026 wurden Claude-SearchBot, Claude-User, Meta-WebIndexer, Gemini-Deep-Research, MistralAI-User und weitere eingeführt. Das ai.robots.txt GitHub-Repository (158 Einträge, Stand März 2026) ist die beste Quelle für aktuelle Bot-Listen.
Ja — mit pfadbasierten Regeln. Beispiel: User-agent: GPTBot / Allow: /blog/ / Disallow: / — erlaubt GPTBot nur den Blog-Bereich und blockiert alles andere. So kannst du z.B. Blog-Content für Training freigeben, aber Produktseiten oder geschützte Bereiche sperren.
llms.txt ist ein vorgeschlagener Standard (Jeremy Howard, September 2024) — eine Markdown-Datei die KI-Systemen eine kuratierte Übersicht deiner Website bietet. ~844.000 Websites haben sie implementiert. Aber: Kein einziger großer KI-Anbieter nutzt llms.txt offiziell. Semrush testete es und fand null Crawler-Besuche. Unsere Empfehlung: Nice-to-have, aber investiere deine Zeit lieber in robots.txt und Content-Optimierung.
Nur wenn du die Such-Bots blockierst. Training-Bots (GPTBot, ClaudeBot, Google-Extended) blockieren hat KEINEN negativen Einfluss auf deine Sichtbarkeit in ChatGPT Search, Claude oder Google AI Overviews. Pixelmojo hat es getestet: Nach Blockierung von 12 Training-Crawlern wuchsen die Citations weiter und die Server-Last sank.
robots.txt allein reicht bei Bytespider oft nicht. Zusätzlich: (1) Cloudflare AI Crawl Control aktivieren, (2) IP-Blocking über .htaccess oder Nginx, (3) User-Agent-basierte Firewall-Regeln. Bytespider ist bis zu 25× aggressiver als GPTBot und machte bei manchen Hosts 90 % des KI-Crawler-Traffics aus (HAProxy).
Direkt: Nein — robots.txt ist kein Ranking-Faktor. Indirekt: Ja — wenn du versehentlich Googlebot blockierst, verlierst du alle Google-Rankings. Und wenn du Google-Extended blockierst, hat das keinen Einfluss auf Rankings oder AI Overviews. Die häufigste Falle: Ein generisches 'Disallow: /' für alle User-Agents, das auch Googlebot trifft.
Drei Methoden: (1) Google Search Console → robots.txt-Tester — zeigt ob Googlebot blockiert ist. (2) Direkt im Browser aufrufen: deine-domain.de/robots.txt — prüfe die Syntax manuell. (3) Server-Logs analysieren — schaue ob blockierte Bots trotzdem crawlen (besonders Bytespider und GrokBot). Tools wie Cloudflare Dashboard zeigen dir den Bot-Traffic in Echtzeit.


