

Zuletzt aktualisiert am

Das Wichtigste in Kürze
Fünf Quellen pro Antwort.
Mehr gibt Perplexity nicht. Während ChatGPT 10,42 Quellen pro Antwort zitiert und Google AI Overviews 9,26 Links einblendet, zeigt Perplexity im Schnitt nur 5,01 (SE Ranking, 46.299 analysierte Links). Das bedeutet: Bei 780 Millionen Queries pro Monat (Bloomberg Tech Summit, Mai 2025) entscheidet Perplexity für jede einzelne Frage, welche fünf Websites zitiert werden — und welche Tausende leer ausgehen.
45 Millionen aktive Nutzer hat die Plattform im März 2026. 5,29 % des gesamten Traffics kommen aus Deutschland — das macht den DACH-Raum zum drittgrößten Markt weltweit nach den USA (18,77 %) und Indien (15,26 %). Die Bewertung: 20 Milliarden Dollar (TechCrunch, September 2025). Der Jahresumsatz: geschätzt 200 Millionen Dollar ARR, ein Wachstum von 800 % gegenüber dem Vorjahr (DemandSage).
Die kompletten Nutzerzahlen aller KI-Suchmaschinen findest du in unserem GEO-Statistiken-Artikel mit 50+ Datenpunkten. Hier geht es um eine einzige Frage: Wie schaffst du es in diese fünf Zitationsplätze?
Perplexity nennt sich selbst „Answer Engine“ — keine klassische Suchmaschine. Der CEO Aravind Srinivas (ehemals OpenAI, Google Brain, DeepMind) formuliert es so: „Wir müssen Google nicht schlagen. Wir machen, was Google nicht machen will.“ Was das für deine Perplexity Optimierung konkret bedeutet, zeigen wir dir mit Daten aus 680 Millionen analysierten Zitationen, der Princeton-GEO-Studie und den offiziellen Perplexity-Dokumentationen.
Die Grundlagen zur KI-Sichtbarkeit insgesamt haben wir in unserem vollständigen GEO-Guide behandelt; technisch erklären wir an anderer Stelle, wie KI-Suchmaschinen funktionieren. Dieser Artikel geht Perplexity-spezifisch in die Tiefe.
Kein klassischer Index.
Perplexity nutzt eine 4-stufige RAG-Pipeline (Retrieval-Augmented Generation), die sich fundamental von Googles Crawl-Index-Rank-Modell unterscheidet. Die gesamte Ranking-Infrastruktur basiert auf Vespa.ai — dem gleichen System, das auch Yahoo und Spotify für Echtzeit-Retrieval einsetzen (Vespa.ai Blog).
| Stufe | Was passiert | Warum es für dich relevant ist |
|---|---|---|
| 1. Indexing | Webseiten werden in numerische Vektoren (Embeddings) umgewandelt und in spezialisierten Datenbanken gespeichert | Dein Content muss crawlbar sein — PerplexityBot muss Zugang haben |
| 2. Retrieval | Bei User-Anfragen findet das System relevante Dokumente durch Vektor-Ähnlichkeitsvergleich + Keyword-Matching (Hybrid Retrieval) | Semantische Relevanz UND exakte Keywords müssen stimmen |
| 3. Augmentation | Gefundene Dokumente werden als Kontext in das Sprachmodell eingespeist — zur Faktenverifikation | Dein Content muss verifizierbare Fakten enthalten, nicht nur Meinungen |
| 4. Generation | Das LLM kombiniert vortrainiertes Wissen mit frisch abgerufenen Daten für quellenbasierte Antworten | Nur Content der den LLM-Qualitätsfilter übersteht, wird zitiert |
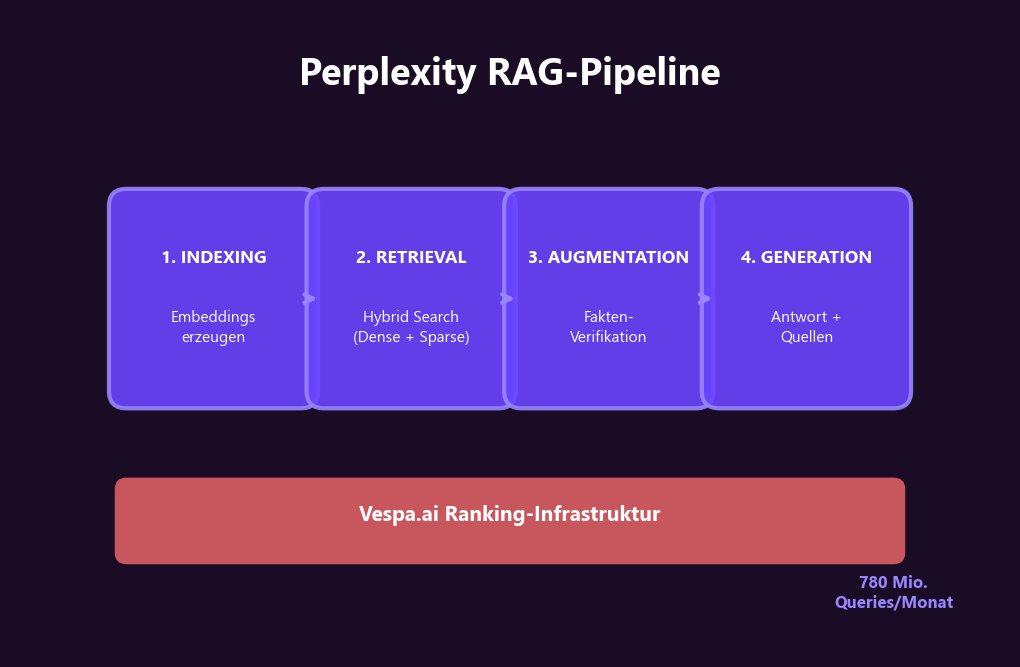
Anders als Google, das primär auf Link-Graphen und PageRank setzt, kombiniert Perplexity zwei Retrieval-Methoden gleichzeitig (Vespa.ai Blog):
Die frühen Stufen nutzen „lexikalische und Embedding-basierte Scorer optimiert auf Geschwindigkeit“, die späteren Stufen wenden „leistungsfähigere Cross-Encoder Reranker-Modelle“ an (Vespa.ai). Das System bewertet nicht ganze Seiten, sondern einzelne Abschnitte — sogenannte Chunks. Ein 3.000-Wörter-Artikel wird in Dutzende Abschnitte zerlegt, und jeder wird einzeln nach Relevanz bewertet.
Was das für dich bedeutet: Jeder einzelne Absatz deines Contents muss für sich allein bestehen können. Ein brillanter Einleitungssatz rettet keinen schwachen Mittelteil. Perplexity pickt die besten Chunks — nicht die beste Seite.
Die Unterschiede zwischen allen KI-Suchmaschinen-Architekturen haben wir im Vergleich GEO vs. SEO detailliert aufgeschlüsselt.
64 % hängen von einem Faktor ab.
First Page Sage hat 11.128 Queries auf Perplexity analysiert und die Gewichtung der Ranking-Faktoren gemessen. Das Ergebnis ist überraschend — und hat wenig mit klassischem SEO zu tun.
| Faktor | Gewichtung | Was das bedeutet |
|---|---|---|
| Erwähnungen in autoritativen Listen | 64 % | Wie oft dein Unternehmen in „Best of“-Listen, Vergleichsportalen, Branchenverzeichnissen erscheint |
| Online-Reviews | 31 % | Bewertungen auf Google, Trustpilot, G2, Capterra — Anzahl UND Qualität |
| Awards/Zertifizierungen | 5 % | Branchenpreise, ISO-Zertifizierungen, offizielle Partnerschaften |
Perplexity zieht sich Empfehlungen aus den Top-5 Google-Ergebnissen, wählt 2-3 autoritative Listen daraus, und ordnet die Ergebnisse primär nach Review-Bewertungen (First Page Sage). Das ist ein fundamental anderer Ansatz als Googles Link-basiertes Ranking.
Bei lokalen Queries verschiebt sich die Gewichtung deutlich:
| Faktor | Gewichtung (lokal) |
|---|---|
| Local Business Reviews | 39 % |
| Authoritative List Mentions | 34 % |
| Online Reviews | 27 % |
Reviews dominieren bei lokalen Suchen — zusammen machen sie 66 % der Gewichtung aus. Für lokale Unternehmen bedeutet das: Google-Bewertungen sind nicht nur für Google Maps relevant, sondern direkt für die Perplexity-Sichtbarkeit.
Content der innerhalb des letzten Monats aktualisiert wurde, wird 3,2× häufiger von Perplexity zitiert als Content älter als 6 Monate (TrySight). AEO-optimierter Content erscheint innerhalb von 3-5 Werktagen in Perplexity-Ergebnissen — deutlich schneller als bei Google, wo neue Seiten oft Wochen auf Rankings warten.
Die Princeton-Studie hat zusätzlich belegt, welche Content-Methoden tatsächlich wirken — und welche nicht. Den vollständigen Überblick dazu findest du in unserem Artikel zur Princeton-GEO-Studie.
75 % Unterschied.
Die Domain-Überschneidung zwischen Perplexity-Citations und Google-Top-Ergebnissen liegt bei nur 18,52 %. Zwischen Perplexity und ChatGPT sind es 25,19 %. Das heißt: Drei von vier Quellen, die Perplexity zitiert, erscheinen weder in Googles Top-10 noch in ChatGPT-Antworten (SE Ranking, 46.299 analysierte Links).
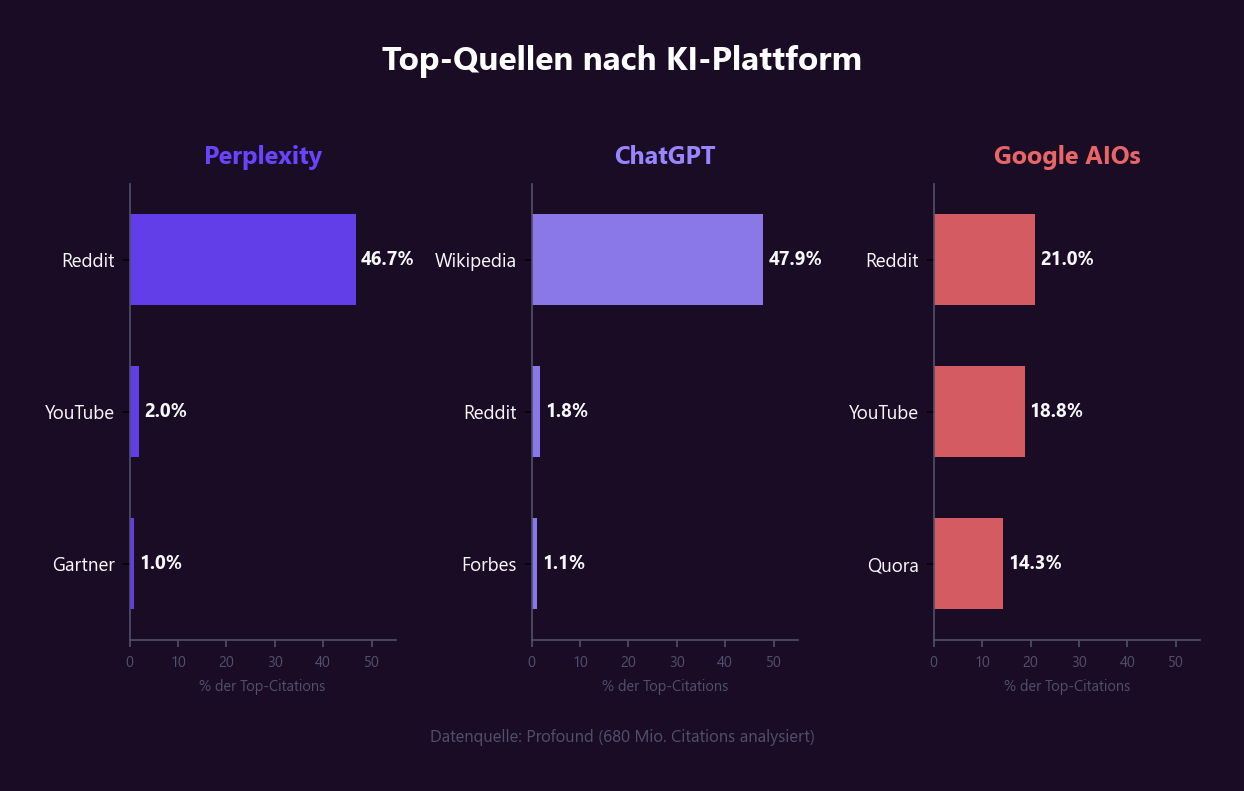
Das Profound-Research-Team hat 680 Millionen Zitationen über alle großen KI-Plattformen analysiert. Das Ergebnis zeigt klare Plattform-Persönlichkeiten:
| Plattform | Bevorzugte Top-Quelle | Anteil an Top-Citations |
|---|---|---|
| Perplexity | 46,7 % | |
| ChatGPT | Wikipedia | 47,9 % |
| Google AI Overviews | Reddit (21 %), YouTube (18,8 %), Quora (14,3 %) | Diversifiziert |
| Metrik | ChatGPT | Perplexity | Google AIOs |
|---|---|---|---|
| Links pro Antwort | 10,42 | 5,01 | 9,26 |
| Domain-Duplikationsrate | 71,03 % | 25,11 % | 58,49 % |
| Antwortlänge (Wörter) | 318 | 257 | 191 |
| Bevorzugtes Domain-Alter | 45,80 % über 15 Jahre | 26,16 % zwischen 10-15 Jahre | 49,21 % über 15 Jahre |
Zwei Erkenntnisse stechen heraus. Erstens: Perplexity hat die niedrigste Domain-Duplikationsrate aller Plattformen (25,11 % vs. ChatGPTs 71,03 %). Das heißt, Perplexity bevorzugt Quellen-Vielfalt — es zitiert selten dieselbe Domain zweimal. Zweitens: Perplexity ist offener für jüngere Domains. Während Google und ChatGPT Domains über 15 Jahre bevorzugen, liegt Perplexitys Sweet Spot bei 10-15 Jahren.
Und ein Detail für Tech-Unternehmen: Perplexity zeigt eine 2,93 % Rate für die .ai-TLD — deutlich höher als jede andere Plattform. KI-bezogene Domains erhalten einen messbaren Vorteil.
Wie sich diese Unterschiede auf Google AI Overviews auswirken, haben wir in unserem Guide zu Google AI Overviews & AI Mode aufgeschlüsselt. Für ChatGPT-spezifische Optimierung: ChatGPT SEO — so wird dein Unternehmen gefunden.
Drei Methoden bringen 80 % des Ergebnisses.
Die Princeton-GEO-Studie hat 9 Optimierungsmethoden in kontrollierten Experimenten getestet. Drei davon dominieren — und sie wirken auch auf echten Perplexity-Systemen (validiert mit +22 % Verbesserung). Keyword Stuffing dagegen performt schlechter als die Baseline (KDD ’24, Aggarwal et al.).
| Methode | Verbesserung | Praxis-Beispiel |
|---|---|---|
| Zitate einbauen (Quotation Addition) | +40 % | „Laut Aravind Srinivas, CEO von Perplexity: ‚Wir müssen Google nicht schlagen.'“ statt „Perplexity will anders sein als Google“ |
| Statistiken hinzufügen (Statistics Addition) | +37 % | „780 Mio. Queries/Monat, 45 Mio. MAU, $200 Mio. ARR“ statt „Perplexity wächst stark“ |
| Quellen angeben (Citation Inclusion) | Bis +115 % | „(SE Ranking, 46.299 Links analysiert)“ statt unbelegte Behauptungen |
Der +115 %-Wert gilt speziell für schlechter gerankte Websites (Rang 5+). Die Studie zeigt: Je weniger Autorität deine Domain hat, desto mehr profitierst du von expliziten Quellenangaben. Für Unternehmen ohne starke Backlink-Profile ist das die effektivste Hebel.
1. Answer-First-Struktur: Beantworte die Frage im ersten Absatz — direkt, mit Zahlen. Nicht: „SEO ist ein wichtiges Thema.“ Sondern: „Perplexity zitiert 5,01 Quellen pro Antwort. So schaffst du es auf einen dieser Plätze.“ Perplexity bewertet einzelne Chunks, nicht ganze Seiten.
2. Statistiken mit Quellenangabe: Jede Behauptung braucht eine Zahl und eine Quelle. „E-Mail-Marketing liefert starken ROI“ wird nicht zitiert. „E-Mail-Marketing liefert 36 $ ROI pro investiertem 1 $ (Litmus, 2024)“ wird zitiert.
3. Experten-Zitate einbauen: Direkte Zitate von Branchenexperten, Studienautoren oder CEOs erhöhen die Zitationswahrscheinlichkeit um 40 % (Princeton-Studie). Perplexity cross-referenziert Autoren-Entitäten über das Web — wer konsistent in seinem Fachbereich publiziert, bekommt mehr Citations.
4. Tabellen und strukturierte Daten: Perplexity extrahiert bevorzugt aus Bullet Lists (Gen-Optima). Tabellen, nummerierte Listen und klare H2/H3-Strukturen sind das Äquivalent von „maschinenlesbarem Content“. ChatGPT bevorzugt Vergleichstabellen, Copilot narrative Zusammenfassungen — wer alle Formate auf einer Seite kombiniert, maximiert die Cross-Plattform-Abdeckung.
5. Content-Frische: Aktualisiere Content mindestens quartalsweise. Zeige datePublished und dateModified sichtbar an. Nutze Jahresangaben in Überschriften („2026 Guide“). Der 3,2×-Faktor gilt: Frischer Content wird massiv bevorzugt.
Du willst wissen, wie sichtbar dein Unternehmen in Perplexity, ChatGPT und Google AI Overviews ist?
In unserer kostenlosen GEO-Analyse prüfen wir deine KI-Sichtbarkeit über alle Plattformen — mit konkreten Maßnahmen, nicht Theorie.
→ Jetzt kostenlose GEO-Analyse anfordern Wie du in allen KI-Suchmaschinen sichtbar werden, zeigt unser Guide dazu.
6. Autoritative Listen-Präsenz: 64 % der Perplexity-Quellenauswahl basiert auf Erwähnungen in autoritativen Listen. Sorge dafür, dass dein Unternehmen auf relevanten „Best of“-Listen, Vergleichsportalen und Branchenverzeichnissen erscheint — G2, Capterra, OMR Reviews, Trustpilot.
7. Online-Reviews systematisch aufbauen: 31 % der Gewichtung. Perplexity ordnet Ergebnisse primär nach Review-Bewertungen. Fordere aktiv Bewertungen von zufriedenen Kunden an — auf Google Business, Trustpilot, branchenspezifischen Portalen.
8. H2/H3 als Fragen formulieren: Perplexity-Nutzer suchen nach Vergleichen („X vs Y“), Best-of-Listen, How-to-Guides und Definitionen. Formuliere Überschriften als natürliche Fragen: „Wie funktioniert Perplexity?“ statt „Perplexity Funktionsweise“.
9. FAQ-Sektionen im Q&A-Format: FAQPage-Schema wird von KI-Suchmaschinen bevorzugt extrahiert. Jede FAQ-Antwort sollte 40-120 Wörter lang sein, eigenständig verständlich und mit einer konkreten Zahl oder Quelle verankert.
10. Autoren-Profil aufbauen: Detaillierte Autoren-Bios mit Qualifikationen, professionellen Links und konsistenter Publikations-Historie. Perplexity cross-referenziert Autoren-Entitäten — Expertise ist kein abstraktes Konzept, sondern ein messbares Signal.
Zwei Bots, zwei Regeln.
Perplexity betreibt zwei getrennte Crawler — und sie verhalten sich grundlegend unterschiedlich (offizielle Perplexity-Dokumentation):
| Bot | Funktion | Respektiert robots.txt? |
|---|---|---|
| PerplexityBot | Automatisiertes Indexing für Suchergebnisse | Ja |
| Perplexity-User | User-initiierte On-Demand-Anfragen | Nein — ignoriert robots.txt generell |
Der entscheidende Unterschied: Perplexity-User wird durch echte Nutzeranfragen ausgelöst und ignoriert robots.txt. Wenn ein Perplexity-Nutzer eine Frage stellt und dein Content relevant ist, greift der Perplexity-User-Bot direkt zu — unabhängig von deiner robots.txt-Konfiguration. Keiner der beiden Crawler sammelt Trainingsdaten für Foundation Models.
Für maximale Perplexity-Sichtbarkeit trägst du folgende Zeilen in deine robots.txt ein:
User-agent: PerplexityBot
Allow: /
User-agent: Perplexity-User
Allow: /Zusätzlich für die anderen KI-Crawler — den vollständigen Überblick findest du in unserem geplanten robots.txt-Guide für KI-Crawler:
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: Google-Extended
Allow: /Viele Websites nutzen Web Application Firewalls (Cloudflare, Sucuri, Wordfence), die unbekannte Bots automatisch blockieren. Wenn dein PerplexityBot in der robots.txt erlaubt ist, aber die WAF ihn blockiert, wird nichts indexiert. Die Lösung: PerplexityBot und Perplexity-User explizit in der WAF whitelisten — per User-Agent-String + IP-Verifizierung (IPs abrufbar unter perplexity.com/perplexitybot.json).
Schema Markup erhöht die KI-Zitationswahrscheinlichkeit um 30 % (Exposure Ninja). Drei Schema-Typen sind für die Perplexity Optimierung besonders relevant:
Ergänze deine robots-Meta-Tags um max-snippet:-1 — das erlaubt KI-Crawlern, unbegrenzt lange Snippets zu extrahieren. Und setze article:modified_time für explizite Aktualitäts-Signale.
Wenn Perplexity deinen PerplexityBot blockiert findet: Die Domain, Headline und eine kurze faktische Zusammenfassung können trotzdem indexiert werden. Aber der Volltext — und damit die Chance auf echte Zitationen — geht verloren (Perplexity Help Center).
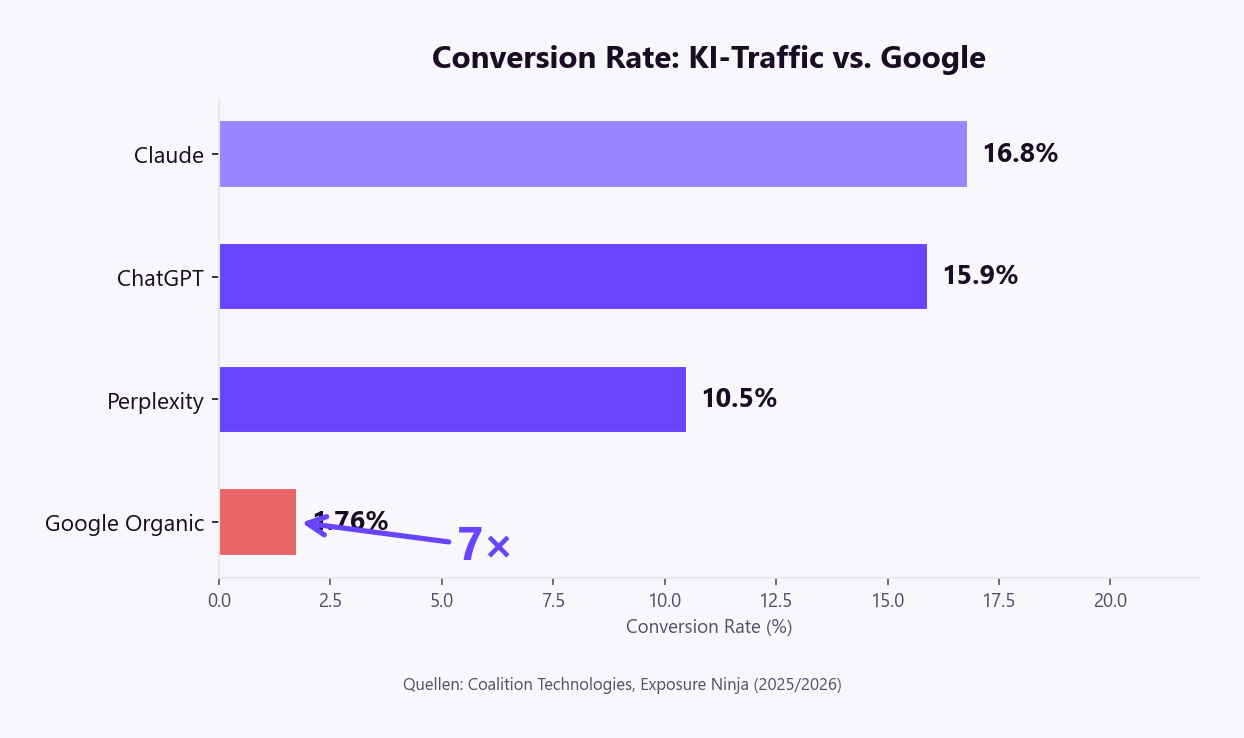
10,5 % Conversion Rate.
Perplexity-Traffic konvertiert mit 10,5 % — gegenüber 1,76 % bei Google Organic (Coalition Technologies). Das ist kein Ausreißer: Claude liegt bei 16,8 %, ChatGPT bei 15,9 %. KI-Suchmaschinen-Traffic ist grundsätzlich wertvoller, weil die Nutzer bereits qualifiziert und im Entscheidungsmodus sind, wenn sie auf eine Citation klicken.
9 von 10 B2B-Software-Käufern nutzen KI-Plattformen (ChatGPT, Perplexity, Claude, Gemini) für ihre Recherche (G2 Reach). Und die Nutzung ist nicht oberflächlich: 47 % der Perplexity-Queries beinhalten Follow-up-Fragen. 61 % der Nutzer kommen täglich zurück. Perplexity wird nicht einmal kurz gecheckt — es ist Teil des Evaluierungs-Workflows (RankScience).
Für B2B bedeutet das eine fundamentale Verschiebung: Dein Unternehmen muss in den 3-4 Quellen erscheinen, die Perplexity pro Antwort zitiert. Wer dort nicht auftaucht, existiert für einen wachsenden Anteil von Entscheidern nicht.
Brands die in AI-Search für Top-of-Funnel-Queries erwähnt werden, stammen 6,5× häufiger aus Third-Party-Content als aus eigenen Brand-Seiten (Flow Agency). Das heißt: Dein Unternehmensblog allein reicht nicht. Du brauchst Erwähnungen in Vergleichsartikeln, Branchenberichten, Reddit-Diskussionen und Review-Portalen.
Die Top 20 Domains fangen 66 % aller KI-Citations ein (Leadscale). Wer nicht in diesen Cluster gehört, muss über Nischen-Autorität reinkommen — spezialisierter Content zu eng definierten Themen, wo die Großen nicht abdecken.
B2B-Käufer formulieren auf Perplexity kontextuellere Fragen als auf Google: Sie nennen Budget, Unternehmensgröße und Compliance-Anforderungen direkt im Prompt. Detaillierte Vergleichs-Guides und strukturierte Evaluierungs-Frameworks generieren mehr Citations als Werbematerial. Perplexity filtert Marketing-Sprache — Fakten, Zahlen und neutrale Vergleiche gewinnen.
Notwendig für B2B-Sichtbarkeit: Strukturierte Pricing-Daten, zugängliche Compliance-Zertifizierungen (ISO 27001, SOC 2, DSGVO) in maschinenlesbaren Formaten und echte Case Studies mit konkreten Zahlen — nicht „signifikante Verbesserung“, sondern „von 5 Mio. auf 8 Mio. Umsatz in 12 Monaten“.
Null Anzeigen. Null bezahlte Platzierungen.
Im Februar 2026 hat Perplexity alle Werbeformate komplett eingestellt — keine Sponsored Questions, keine bezahlten Ergebnisse, nichts (MacRumors, PYMNTS). Die Begründung der Perplexity-Führung: „Ein Nutzer muss glauben, dass eine Antwort die bestmögliche ist. Sobald Werbung in Ergebnissen erscheint, beginnen Nutzer jede Antwort in Frage zu stellen.“
Das ist ein strategischer Gegentrend. Während OpenAI gerade Werbetests in ChatGPT startet und Google AI Overviews mit integrierten Anzeigen ausrollt, positioniert sich Perplexity explizit als werbefreie Alternative. Das Monetarisierungsmodell basiert ausschließlich auf Subscriptions (Pro $20/Monat, Enterprise $40-325/User/Monat) und API-Revenue (Sonar API).
Jeder einzelne Zitationsplatz in Perplexity ist organisch. Es gibt keine Möglichkeit, sich reinzukaufen. Content-Qualität, Autorität und Relevanz entscheiden allein. Das macht die Perplexity Optimierung einerseits schwieriger (kein Shortcut über Budget), andererseits fairer — wer den besten Content liefert, gewinnt.
Perplexity hat stattdessen ein Revenue-Sharing-Modell mit Publishern etabliert. Der Spiegel und RTL Germany (stern, ntv) waren unter den ersten deutschen Partnern. Der Comet Plus Pool: 42,5 Millionen Dollar, davon 80 % an Publisher-Programm-Teilnehmer (Digiday). Das bedeutet: Deutsche Premium-Medien haben bereits einen bevorzugten Status — und ihre Inhalte werden prioritär zitiert.
Für Unternehmen, die keine Publisher sind, gilt umso mehr: Wer in Artikeln dieser Publisher erwähnt wird (Gastbeiträge, Experteninterviews, Case Studies), profitiert doppelt — vom Publisher-Boost und von der eigenen Markennennung.
Nicht raten — messen.
Perplexity sendet automatisch Referrer-Header bei Citation-Klicks — kein UTM-Tagging nötig. Aber du musst wissen, wo du nachschauen musst.
perplexity.aiperplexity|chatgpt|claude|gemini|copilot| Tool | Stärke | Preis |
|---|---|---|
| OtterlyAI | All-around AI-Monitoring (ChatGPT, Perplexity, Google AIOs, Gemini, Copilot) | Ab $49/Monat |
| SE Ranking | Perplexity Visibility Tracker + klassisches SEO | Ab $65/Monat |
| Ziptie.dev | Perplexity-fokussiertes Tracking | Starter kostenlos |
| Profound | Enterprise-Analyse über alle AI-Plattformen | Auf Anfrage |
Wichtig: Teste 20-30 Target-Queries wöchentlich. Nutze die realen Fragen, die deine Zielgruppe stellt — nicht die Keywords, für die du bei Google rankst. Die Überschneidung liegt, wie gesagt, bei nur 25 %.
Eine Plattform reicht nicht.
Perplexity hat 5,8 % Marktanteil. ChatGPT hat 60,4 %. Google Gemini hat 15,2 %. Microsoft Copilot hat 12,9 % (First Page Sage, März 2026). Wer nur für eine Plattform optimiert, verschenkt 94 % des KI-Suchmarktes.
Aber: 89 % der KI-Citations kommen von unterschiedlichen Domains — die Plattformen diversifizieren ihre Quellen aktiv (Exposure Ninja). Und 40 % der zitierten Quellen ranken außerhalb der Top-10 in traditionellen Suchergebnissen. Das heißt: GEO ist eine eigenständige Disziplin, kein Anhängsel von SEO.
Schritt 1 — SEO als Fundament: Crawlbarkeit, Indexierung, technische Basics. Ohne SEO kein GEO. Die Unterschiede haben wir in unserem GEO vs. SEO Vergleich detailliert erklärt.
Schritt 2 — Plattform-übergreifende Grundlagen: Answer Capsules (40-120 Wörter, eigenständig verständlich), Tabellen, FAQ-Schema, Quellenangaben. Diese Elemente wirken auf allen KI-Plattformen gleichzeitig.
Schritt 3 — Plattform-spezifische Optimierung: Perplexity bevorzugt Reddit-Präsenz und autoritative Listen. ChatGPT gewichtet Referring Domains und Wikipedia-Verlinkungen. Google AI Overviews favorisiert YouTube-Content. Optimiere für jede Plattform das eine Signal, das den größten Hebel hat.
Schritt 4 — Messen und iterieren: Tracke deine Sichtbarkeit auf allen Plattformen parallel. AI-Referral-Traffic wächst mit +357 % pro Jahr (Exposure Ninja, Juni 2025 vs. 2024). Wer jetzt die Infrastruktur aufbaut, profitiert überproportional.
Der AI-Referral-Traffic hat im Juni 2025 die Marke von 1,13 Milliarden Visits pro Monat erreicht — bei einem Wachstum von +155,6 % gegenüber dem Vorjahr. Zum Vergleich: Organic Search wuchs nur +24 %, Social +21,5 %, Direct +14,9 %.
Ob SEO wirklich „tot“ ist oder GEO es nur ergänzt, haben wir datenbasiert in unserem Artikel Ist SEO tot? analysiert.
Die vollständige GEO-Strategie — mit allen Plattformen, allen Methoden, allen Metriken — findest du in unserem kompletten GEO-Guide. Und wenn du das nicht allein umsetzen willst: Mehr zu unserer GEO-Agentur.
Um deine Website für Perplexity zu optimieren, machst du deine Inhalte als zitierfähige Quelle erkennbar und stellst sicher, dass der PerplexityBot sie crawlen darf. Die fünf wichtigsten Schritte:
1. PerplexityBot erlauben: In der robots.txt sicherstellen, dass PerplexityBot und Perplexity-User nicht blockiert sind.
2. Antwort-Passagen schreiben: Jede zentrale Frage im ersten Satz vollständig beantworten (40-60 Wörter), ohne Kontext drumherum.
3. Struktur und Schema: Klare H2-Fragen, Listen, Tabellen und Schema-Markup (FAQPage, Article) erleichtern die Extraktion.
4. Quellen und Aktualität: Perplexity bevorzugt belegte, aktuelle Inhalte mit Datum und nachvollziehbaren Quellen.
5. Marken-Erwähnungen aufbauen: Perplexity zitiert bevorzugt Seiten, deren Marke auch auf Drittquellen wie Reddit, Fachmedien und Wikipedia auftaucht.
Perplexity AI ist eine KI-basierte Answer Engine, die 2022 von Aravind Srinivas (ehemals OpenAI, Google Brain) gegründet wurde. Sie nutzt eine RAG-Pipeline (Retrieval-Augmented Generation), um Fragen mit quellenbasierten Antworten zu beantworten — inklusive Inline-Zitationen. Im März 2026 hat Perplexity 45 Mio. aktive Nutzer, verarbeitet 780 Mio. Queries pro Monat und hält 5,8 % Marktanteil bei KI-Chatbots (DemandSage, First Page Sage).
Perplexity Optimierung bedeutet, deine Inhalte so zu strukturieren, dass sie von Perplexitys RAG-Pipeline als zitierfähige Quelle erkannt werden. Die drei wirksamsten Methoden laut Princeton-Studie: Experten-Zitate einbauen (+40 %), Statistiken mit Quellenangabe hinzufügen (+37 %), und explizite Quellennennungen (+115 % für schwächer gerankte Sites). Technisch: PerplexityBot in der robots.txt erlauben und Schema Markup (Article + FAQ) implementieren.
Drei Voraussetzungen: (1) PerplexityBot und Perplexity-User in der robots.txt erlauben, (2) Content mit Answer-First-Struktur, spezifischen Daten und Quellenangaben erstellen, (3) In autoritativen Listen und Verzeichnissen erscheinen — 64 % der Perplexity-Quellenauswahl basiert auf diesen Listen-Erwähnungen (First Page Sage, 11.128 Queries analysiert). Content der im letzten Monat aktualisiert wurde, wird 3,2× häufiger zitiert.
Perplexity zitiert im Schnitt 5,01 Quellen pro Antwort, ChatGPT 10,42. Perplexity bevorzugt Reddit als Top-Quelle (46,7 % der Top-Citations), ChatGPT bevorzugt Wikipedia (47,9 %). Die Domain-Überschneidung liegt bei nur 25,19 % — drei von vier Perplexity-Quellen erscheinen nicht in ChatGPT-Antworten. Perplexity hat seit Februar 2026 keine Werbung mehr, ChatGPT testet gerade Anzeigen.
Für maximale Sichtbarkeit: Ja. PerplexityBot ist Perplexitys offizieller Crawler für automatisiertes Indexing und respektiert robots.txt. Der zweite Bot — Perplexity-User — wird durch echte Nutzeranfragen ausgelöst und ignoriert robots.txt generell. Wenn du PerplexityBot blockierst, können Domain, Headline und kurze Zusammenfassungen trotzdem indexiert werden — aber der Volltext fehlt, und damit die Chance auf echte Zitationen.
Drei Wege: (1) GA4 Referral-Traffic filtern nach perplexity.ai — Perplexity sendet automatisch Referrer-Header, kein UTM-Tagging nötig. (2) Dedizierte AI-Monitoring-Tools wie OtterlyAI, SE Ranking oder Ziptie.dev. (3) 20-30 Target-Queries wöchentlich manuell testen — mindestens 2× pro Query, da Perplexity verschiedene LLM-Modelle nutzt und die Ergebnisse variieren.
Perplexity-Traffic konvertiert mit 10,5 % — 7× besser als Google Organic mit 1,76 % (Coalition Technologies). Der Grund: Nutzer sind bereits qualifiziert und im Entscheidungsmodus, wenn sie auf Citations klicken. AI-Search-Traffic insgesamt konvertiert mit 14,2 % vs. Googles 2,8 % (Exposure Ninja). Die Sessions sind länger und die Kaufbereitschaft höher als bei klassischem Suchtraffic.
Nein — seit Februar 2026 hat Perplexity sämtliche Werbeformate eingestellt. Keine Sponsored Questions, keine bezahlten Platzierungen. Die Begründung: Vertrauen in die Antwortqualität soll nicht durch Werbung untergraben werden. Das Geschäftsmodell basiert ausschließlich auf Subscriptions (Pro $20/Monat, Enterprise $40-325/Monat) und API-Revenue. Alle Zitationsplätze in Perplexity sind organisch.
Drei Schema-Typen sind besonders relevant: (1) Article Schema mit author, datePublished, dateModified und publisher — signalisiert Aktualität und Autorschaft. (2) FAQPage Schema — wird direkt von KI-Suchmaschinen extrahiert. (3) HowTo Schema für Schritt-für-Schritt-Anleitungen. Schema Markup erhöht die KI-Zitationswahrscheinlichkeit um 30 % (Exposure Ninja). Ergänze max-snippet:-1 in den robots-Meta-Tags.
Besonders für kleine Unternehmen. Die Princeton-Studie zeigt: Schlechter gerankte Websites (Rang 5+) profitieren am stärksten von GEO-Methoden — bis zu +115 % Sichtbarkeitssteigerung durch Quellenangaben. Perplexity ist offener für jüngere Domains als Google oder ChatGPT. Und 40 % der von KI-Plattformen zitierten Quellen ranken außerhalb der Google-Top-10. Die Eintrittsbarriere ist niedriger als bei Google.


