

Zuletzt aktualisiert am
Das Wichtigste in Kürze
844.000 Websites haben llms.txt installiert. Effekt: nicht messbar.
Das ist die Kurzversion. Die Langversion erfordert einen genaueren Blick auf die Daten — denn llms.txt ist eines dieser Themen, bei denen die Stimmung in der SEO-Community weit vor den Fakten liegt. LinkedIn-Posts feiern die Datei als „den neuen Standard für KI-Sichtbarkeit“. GEO-Guides listen llms.txt als Pflichtmaßnahme. Und in fast jedem Webinar zu Generative Engine Optimization fällt der Satz: „Erstellt euch eine llms.txt.“
Dann die Gegenseite: Eine OtterlyAI-Studie über 90 Tage zeigt, dass exakt 0,1 % aller AI-Requests an Websites über llms.txt laufen. Eine Analyse von 300.000 Domains findet keinen messbaren Effekt auf KI-Zitationen. Und Googles John Mueller sagt öffentlich: „No AI system currently uses llms.txt.“
In diesem Artikel analysieren wir die Datenlage — ohne Hype und ohne Pauschalablehnung. Du erfährst, was llms.txt ist, warum die Adoption bei den größten Websites bei exakt 0,0 % liegt, und was stattdessen nachweislich für KI-Sichtbarkeit sorgt. Die Grundlagen zu Generative Engine Optimization findest du in unserem GEO-Guide. Hier geht es um eine einzelne Taktik — und ob sie hält, was die Community verspricht.
Eine Markdown-Datei im Root-Verzeichnis deiner Website.
llms.txt wurde im September 2024 von Jeremy Howard vorgeschlagen — dem Gründer von FastAI und AnswerAI, bekannt für seine Arbeit im Deep Learning. Die Idee: Websites stellen LLMs (Large Language Models) eine maschinenlesbare Zusammenfassung ihrer Inhalte bereit. Nicht als HTML, nicht als XML, sondern als einfaches Markdown in einer .txt-Datei.
Die Datei liegt unter domain.de/llms.txt und enthält:
Neben der kompakten llms.txt gibt es eine optionale Erweiterung: llms-full.txt. Diese enthält den kompletten Content aller verlinkten Seiten — zusammengefasst in einer einzigen Datei. Die Logik dahinter: LLMs müssen nicht jede Unterseite einzeln crawlen, sondern bekommen alles auf einen Schlag.
Wichtig: llms.txt ist KEIN offizieller Standard. Keine IETF-Spezifikation. Kein W3C-Standard. Es ist ein Community-Proposal — ein Vorschlag, der Traktion bekommen hat, aber von keiner Standardisierungsorganisation formal anerkannt wurde.
Türsteher vs. Visitenkarte. Das ist der Kernunterschied.
robots.txt gibt es seit 1994. Die Datei steuert, welche Bots welche Seiten crawlen dürfen — und welche nicht. Seit der RFC 9309 ist robots.txt ein formalisierter Standard. Seriöse Crawler respektieren die Anweisungen. Und für KI-Sichtbarkeit ist robots.txt direkt relevant: Wer GPTBot, ClaudeBot oder PerplexityBot blockiert, wird von diesen Plattformen nicht indexiert. Mehr dazu in unserem Guide zu robots.txt für KI-Crawler.
llms.txt funktioniert anders. Die Datei steuert nichts. Sie blockiert nichts. Sie gibt auch keine Anweisungen. Stattdessen informiert sie — sie sagt einem LLM: „Das sind unsere Inhalte, das ist die Struktur, hier findest du was.“
| Eigenschaft | robots.txt | llms.txt |
|---|---|---|
| Zweck | Crawling steuern (Allow/Disallow) | Inhalte zusammenfassen (informieren) |
| Seit | 1994 (RFC 9309) | September 2024 (Community-Proposal) |
| Standard | Ja (IETF) | Nein (kein offizieller Standard) |
| Format | Eigene Syntax | Markdown |
| Durchsetzung | Wird von seriösen Bots respektiert | Keine — kein Bot muss die Datei lesen |
| KI-Relevanz | Direkt: blockiert oder erlaubt KI-Crawler | Indirekt: informiert (ohne bestätigte Nutzung) |
Der entscheidende Punkt: robots.txt hat eine direkte, messbare Wirkung. Blockierst du den GPTBot, erscheint dein Content nicht in ChatGPT. llms.txt hat — Stand heute — keine bestätigte Wirkung auf irgendeine KI-Plattform.
10,13 % Adoption. Klingt ordentlich — bis du genauer hinschaust.
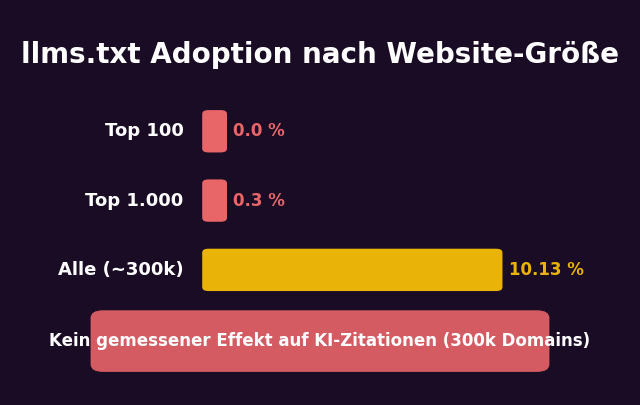
Eine Analyse von 300.000 Domains zeigt: Rund jede zehnte Website hat eine llms.txt-Datei im Root-Verzeichnis. In absoluten Zahlen sind das 844.000+ Websites weltweit (Stand Oktober 2025). Das klingt nach kritischer Masse. Aber die Verteilung erzählt eine andere Geschichte:
Keine der 100 größten Websites der Welt nutzt llms.txt. Nicht Google. Nicht Amazon. Nicht Wikipedia. Nicht YouTube. Die Adoption konzentriert sich fast ausschließlich auf kleinere Websites — und innerhalb dieser Gruppe auf einen bestimmten Typ: Tech-Unternehmen und Developer-Tools.
Die bekanntesten Adopter: Anthropic (die Firma hinter Claude), Cursor (KI-Code-Editor), GitBook, Mintlify und Webflow. Fällt dir etwas auf? Es sind durchweg Unternehmen aus dem KI- und Developer-Ökosystem. Keine E-Commerce-Shops. Keine lokalen Dienstleister. Keine B2B-Unternehmen außerhalb der Tech-Bubble.
Das Muster ist eindeutig: Je größer und etablierter eine Website, desto unwahrscheinlicher die llms.txt-Adoption. Die Websites mit den meisten Ressourcen, den größten SEO-Teams und dem tiefsten KI-Verständnis haben sich bewusst dagegen entschieden.
300.000 Domains analysiert. Ergebnis: null.
Das ist keine Meinung. Das ist eine Datenlage, die schwer zu ignorieren ist. Eine Studie des Search Engine Journal mit 300.000 Domains findet keinen messbaren Effekt von llms.txt auf die Wahrscheinlichkeit, von KI-Suchmaschinen zitiert zu werden. Websites mit llms.txt werden nicht häufiger erwähnt. Sie bekommen nicht mehr KI-Traffic. Ihre Citation Rate steigt nicht.
Drei weitere Datenpunkte bestätigen das Bild:
1. Googles John Mueller: „No AI system currently uses llms.txt.“ Muellers Aussage ist deshalb relevant, weil Google mit AI Overviews und AI Mode die mit Abstand größte KI-Suchfunktion betreibt — mit 1,5 Milliarden Nutzern. Wenn Google llms.txt nicht liest, ist der größte Kanal bereits raus.
2. OtterlyAI 90-Tage-Studie: Über einen Zeitraum von 90 Tagen hat OtterlyAI den Traffic gemessen, der über llms.txt auf Websites gelangt. Das Ergebnis: 0,1 % aller AI-Requests gehen über llms.txt. Die restlichen 99,9 % laufen über traditionelles Crawling — genau wie bei Suchmaschinen.
3. Keine offizielle Bestätigung: Weder OpenAI (ChatGPT), noch Google (AI Overviews/AI Mode), noch Anthropic (Claude Web-Suche), noch Perplexity bestätigen, dass ihre Systeme llms.txt offiziell auslesen und für die Generierung von Antworten nutzen. Zero Major AI Platforms.
Die Daten sind eindeutig: llms.txt hat — Stand März 2026 — keinen nachweisbaren Einfluss auf KI-Sichtbarkeit. Wer seine GEO KPIs trackt, wird durch llms.txt keine Veränderung sehen.
Die Technik hinter KI-Suchmaschinen erklärt das Problem.
KI-Plattformen wie ChatGPT, Perplexity und Google AI Overviews arbeiten mit zwei Mechanismen: Training und Retrieval. Beim Training werden Milliarden von Webseiten verarbeitet — eine einzelne llms.txt-Datei hat in diesem Datensatz statistisch kein Gewicht. Beim Retrieval (Live-Suche) crawlen die Systeme Websites in Echtzeit — genau wie Google. Sie lesen HTML, folgen Links, analysieren Struktur und Content.
Und genau hier liegt das Problem von llms.txt: Es löst kein reales Problem der KI-Systeme.
Das soll nicht heißen, dass llms.txt nie relevant werden kann. Falls eine große KI-Plattform die Datei offiziell unterstützt, ändert sich die Gleichung. Aber Stand heute: Keine Plattform tut das. Und die Daten reflektieren genau das.
llms.txt erstellen dauert 15 Minuten. Herauszufinden, warum KI-Suchmaschinen deine Wettbewerber empfehlen und dich nicht — das erfordert eine systematische Analyse.
Wir prüfen in unserer kostenlosen GEO-Analyse 135 Faktoren: von Crawler-Zugang über Content-Struktur bis zu Schema Markup und Brand-Signalen. Keine Hype-Taktiken. Nur das, was die Daten als wirksam belegen.
Kostenlose GEO-Analyse anfordern →
15 Minuten Aufwand. Null Risiko. Das ist das stärkste Argument.
Nach den bisherigen Daten wäre es logisch zu sagen: „Vergiss llms.txt.“ Aber es gibt eine Gegenperspektive, die wir ehrlich einordnen sollten. Denn „kein messbarer Effekt heute“ ist nicht dasselbe wie „wird nie relevant“.
Argument 1: Zukunftssicherung. Die KI-Suche verändert sich in Monaten, nicht in Jahren. Google AI Overviews gab es vor 18 Monaten nicht. Perplexity hatte vor 2 Jahren kaum Nutzer. Falls eine große Plattform llms.txt in ihre Retrieval-Pipeline integriert, sind die Websites im Vorteil, die die Datei bereits haben. 844.000+ Websites setzen genau darauf.
Argument 2: Keine Opportunitätskosten. llms.txt ist eine einzelne Markdown-Datei. Du lädst sie hoch, fertig. Kein Code. Kein Plugin. Kein Maintenance-Aufwand. Im Vergleich zu Schema Markup (Stunden), Content-Erstellung (Tage) oder Linkbuilding (Wochen) ist llms.txt die günstigste Maßnahme im gesamten GEO-Stack.
Argument 3: Strukturelles Nebenprodukt. Die Erstellung zwingt dich, über die wichtigsten Seiten deiner Website nachzudenken. Was sind die 10-20 Seiten, die ein LLM kennen sollte? Welche Inhalte repräsentieren dein Unternehmen am besten? Diese Klarheit hilft nicht nur theoretisch bei LLMs — sie schärft auch deine Content-Strategie.
Unsere Empfehlung: Implementiere llms.txt — aber investiere keine Stunde mehr als nötig. Und erwarte keinen messbaren Effekt. Es ist eine Versicherung, keine Strategie.
Drei Schritte, 15 Minuten, kein Entwickler nötig.
Schritt 1: Datei erstellen
Öffne einen Texteditor und erstelle eine Datei mit dem Namen llms.txt. Die Datei nutzt Markdown-Syntax. Hier die Grundstruktur:
# Dein Firmenname
> Kurzbeschreibung deines Unternehmens in 1-2 Sätzen.
## Wichtige Seiten
- [Startseite](https://deineseite.de/): Überblick über Leistungen und Angebote
- [Über uns](https://deineseite.de/ueber-uns/): Team, Expertise, Referenzen
- [Leistung A](https://deineseite.de/leistung-a/): Beschreibung der Kernleistung
- [Leistung B](https://deineseite.de/leistung-b/): Beschreibung der zweiten Leistung
- [Blog](https://deineseite.de/blog/): Fachartikel zu [Themengebiet]
- [Kontakt](https://deineseite.de/kontakt/): Kontaktformular und Standort
## Optional: Ressourcen
- [FAQ](https://deineseite.de/faq/): Häufige Fragen zu [Thema]
- [Case Studies](https://deineseite.de/referenzen/): Kundenprojekte mit Ergebnissen
Schritt 2: Hochladen ins Root-Verzeichnis
Die Datei muss unter deineseite.de/llms.txt erreichbar sein — also im Root-Verzeichnis deiner Website. Bei WordPress lädst du die Datei per FTP in den Ordner, in dem auch die wp-config.php liegt. Bei Shopify, Webflow oder anderen Plattformen: prüfe, ob das Root-Verzeichnis zugänglich ist (bei manchen Plattformen ist das eingeschränkt).
Schritt 3 (optional): llms-full.txt erstellen
Die erweiterte Version llms-full.txt enthält den kompletten Content aller verlinkten Seiten in einer Datei. Das ist bei kleinen Websites (unter 20 Seiten) machbar. Bei größeren Websites wird die Datei schnell unhandlich. Unsere Empfehlung: Starte mit der kompakten llms.txt. Die Full-Version ist optional und bringt — nach aktuellem Stand — keinen zusätzlichen Effekt.
Die Adopter zeigen: Es gibt kein einheitliches Format.
Da llms.txt kein offizieller Standard ist, variieren die Implementierungen. Einige Beispiele:
Anthropic (docs.anthropic.com/llms.txt)
Anthropic — die Firma hinter Claude — listet ihre Dokumentationsseiten in einer strukturierten Markdown-Datei. Jeder Link hat eine Kurzbeschreibung. Die Datei konzentriert sich auf API-Dokumentation und Developer-Guides. Kein Marketing-Content, keine Blog-Artikel.
Cursor (cursor.com/llms.txt)
Der KI-Code-Editor Cursor nutzt llms.txt primär für seine Produktdokumentation. Fokus auf Features, Tastenkürzel, Konfiguration. Auch hier: rein technisch, kein Sales-Content.
GitBook & Mintlify
Beide Dokumentations-Plattformen generieren llms.txt automatisch für ihre Kunden. Das erklärt einen Teil der 844.000-Adoption: Viele dieser Websites haben llms.txt nicht bewusst erstellt, sondern es wurde von ihrer Plattform automatisch generiert.

Was auffällt: Alle bekannten Adopter sind Tech-Unternehmen mit Entwickler-Zielgruppen. Für einen IT-Dienstleister, einen Online-Shop oder ein lokales Unternehmen gibt es bislang keine Best-Practice-Referenz — weil diese Zielgruppen llms.txt kaum nutzen.
Vier Hebel mit nachgewiesener Wirkung. Keiner davon heißt llms.txt.
Wenn llms.txt (noch) keinen messbaren Effekt hat — was funktioniert dann? Die Daten zeigen vier Bereiche, die KI-Sichtbarkeit nachweislich beeinflussen:
1. Content-Qualität + E-E-A-T
96 % aller Zitationen in Google AI Overviews stammen von Content mit starkem E-E-A-T — also nachgewiesener Erfahrung, Expertise, Autorität und Vertrauenswürdigkeit (BrightEdge, 2025). KI-Suchmaschinen zitieren nicht den Content mit der hübschesten llms.txt, sondern den Content mit den überzeugendsten Signalen. Web Mentions — also Erwähnungen deiner Marke auf anderen Websites — korrelieren 3× stärker mit KI-Zitationen als klassische Backlinks (Ahrefs, 2025). Die Grundlage dafür: zitierfähiger Content mit klaren Definitionen, konkreten Daten und eigenständigen Passagen.
2. Schema Markup
Strukturierte Daten wie FAQPage, Article und HowTo Schema geben KI-Systemen ein maschinenlesbares Signal darüber, was dein Content enthält — und in welchem Format. Anders als llms.txt werden Schema-Daten von Google nachweislich ausgelesen und für AI Overviews genutzt. Die Details: Schema Markup für GEO.
3. Crawler-Zugang (robots.txt)
OtterlyAI zeigt: 99,9 % aller AI-Requests kommen über traditionelles Crawling. Das heißt: Deine robots.txt für KI-Crawler ist 1.000× wichtiger als deine llms.txt. Wer GPTBot, ClaudeBot und PerplexityBot in der robots.txt blockiert, wird von diesen Plattformen nicht indexiert — unabhängig davon, ob eine llms.txt existiert.
4. Traditionelle SEO-Signale
Google AI Overviews und AI Mode nutzen dieselben Ranking-Signale wie die organische Suche: Content-Tiefe, interne Verlinkung, technische Performance, Domain-Autorität. SEO bleibt das Fundament — GEO ist der Verstärker. Die Kombination beider Disziplinen liefert die stärksten Ergebnisse, wie unser SEO-Guide zeigt.
Das bedeutet nicht, dass llms.txt wertlos ist. Es bedeutet, dass die Prioritäten klar sein müssen. Wer seine GEO-Strategie auf llms.txt statt auf Content, Schema und Crawling aufbaut, investiert in die falsche Stelle. In unserer GEO-Audit Checkliste findest du alle Maßnahmen — priorisiert nach Wirkung.
llms.txt ist eine 15-Minuten-Aufgabe. Behandle sie auch so.
Die Datenlage ist eindeutig: llms.txt hat heute keinen messbaren Effekt auf KI-Zitationen. Keine der großen KI-Plattformen bestätigt eine offizielle Nutzung. Die Top-100-Websites der Welt ignorieren das Format vollständig. Und die einzige Studie mit relevanter Stichprobe (300.000 Domains) findet — nichts.
Gleichzeitig ist llms.txt risikofrei und minimal im Aufwand. Erstelle die Datei. Lade sie hoch. Vergiss sie. Falls in 6 oder 12 Monaten eine KI-Plattform ankündigt, llms.txt offiziell zu unterstützen, hast du einen Vorsprung. Falls nicht, hast du 15 Minuten verloren — und nichts weiter.
Aber mach dir nichts vor: llms.txt ist keine GEO-Strategie. Es ist ein optionaler Dateipfad. Was wirklich zählt, sind die 4 Hebel, die wir in diesem Artikel gezeigt haben — Content-Qualität, Schema Markup, Crawler-Zugang und starke SEO-Signale. Das sind die Faktoren, die 96 % der KI-Zitationen erklären. Diese Hebel setzt auf Wunsch unsere GEO-Agentur für dich um.
In unserem GEO-Tools Vergleich findest du die Plattformen, mit denen du deine ChatGPT Sichtbarkeit und andere KI-Kanäle konkret messen kannst — statt auf ein Format zu setzen, das noch niemand offiziell nutzt.
llms.txt ist eine Markdown-basierte Datei, die im Root-Verzeichnis einer Website platziert wird (domain.de/llms.txt). Vorgeschlagen im September 2024 von Jeremy Howard (FastAI/AnswerAI), soll sie LLMs eine maschinenlesbare Zusammenfassung der Website-Inhalte geben. Es handelt sich um ein Community-Proposal — keinen offiziellen IETF- oder W3C-Standard.
robots.txt steuert das Crawling — sie sagt Bots, welche Seiten sie besuchen dürfen und welche nicht. llms.txt informiert nur — sie beschreibt, welche Inhalte auf der Website existieren. robots.txt ist seit 1994 ein formalisierter Standard (RFC 9309) und wird von Crawlern respektiert. llms.txt hat keinen Standard-Status und keine bestätigte Nutzung durch KI-Plattformen.
Nein. Googles John Mueller hat öffentlich bestätigt: „No AI system currently uses llms.txt.“ Google AI Overviews und AI Mode nutzen traditionelle SEO-Signale — Crawling, Indexierung, Content-Qualität, E-E-A-T und Domain-Autorität.
Es gibt keine offizielle Bestätigung von OpenAI (ChatGPT), Perplexity, Anthropic (Claude) oder einer anderen großen KI-Plattform, dass llms.txt für die Generierung von Antworten verwendet wird. Alle Plattformen crawlen Websites über ihre eigenen Bots (GPTBot, PerplexityBot, ClaudeBot) — wie traditionelle Suchmaschinen.
Stand Oktober 2025: 844.000+ Websites haben llms.txt installiert. Das entspricht 10,13 % von 300.000 analysierten Domains. Allerdings: Die Top-1.000 Websites zeigen nur 0,3 % Adoption. Die Top-100 Websites: 0,0 %. Ein Teil der Adoptionszahl geht auf Plattformen wie GitBook und Mintlify zurück, die llms.txt automatisch generieren.
Nach aktueller Datenlage: Nein. Eine Studie mit 300.000 Domains (Search Engine Journal, 2025) findet keinen messbaren Effekt auf KI-Zitationen. Eine OtterlyAI-Studie über 90 Tage zeigt, dass nur 0,1 % der AI-Requests über llms.txt laufen — 99,9 % gehen über traditionelles Crawling.
Ja — als Low-effort Zukunftsinvestition. Der Aufwand liegt bei 15-30 Minuten, es gibt kein technisches Risiko und null Wartungsaufwand. Falls eine KI-Plattform llms.txt in Zukunft unterstützt, bist du vorbereitet. Aber erwarte keinen aktuellen Effekt auf deine KI-Sichtbarkeit.
llms-full.txt ist die erweiterte Version von llms.txt. Während llms.txt nur Links und Kurzbeschreibungen enthält, beinhaltet llms-full.txt den kompletten Content aller verlinkten Seiten in einer Datei. Bei kleinen Websites (unter 20 Seiten) ist das machbar. Bei größeren Websites wird die Datei schnell unhandlich — und bringt nach aktuellem Stand keinen zusätzlichen Effekt.
Vier Hebel haben nachgewiesene Wirkung: (1) Content-Qualität + E-E-A-T — 96 % der AI-Overview-Zitationen stammen von starkem E-E-A-T Content. (2) Schema Markup — FAQPage, Article, HowTo Schema als maschinenlesbare Signale. (3) Crawler-Zugang — GPTBot, ClaudeBot, PerplexityBot in der robots.txt erlauben. (4) Traditionelle SEO-Signale — Content-Tiefe, interne Verlinkung, technische Performance. Der vollständige Überblick: GEO-Guide.
Erstelle eine Textdatei mit dem Namen llms.txt. Nutze Markdown-Syntax: Website-Titel als H1, Kurzbeschreibung, dann Links zu den wichtigsten Seiten mit jeweils einer Beschreibung. Lade die Datei ins Root-Verzeichnis deiner Website (so dass sie unter domain.de/llms.txt erreichbar ist). Der gesamte Prozess dauert 15-30 Minuten.


